How to Ingest and Analyze Data in Amazon Athena

This is a legacy platform changelog. The information reflected here may not represent current functionality and some links may be broken.
Amazon Athena allows you easily query data stored in Amazon S3 with SQL. With Meroxa, you can build a pipeline to pull data from any source and send it to Amazon S3 in real-time. Altogether, this pipeline allows you to query and analyze real-time data across multiple sources using Athena.
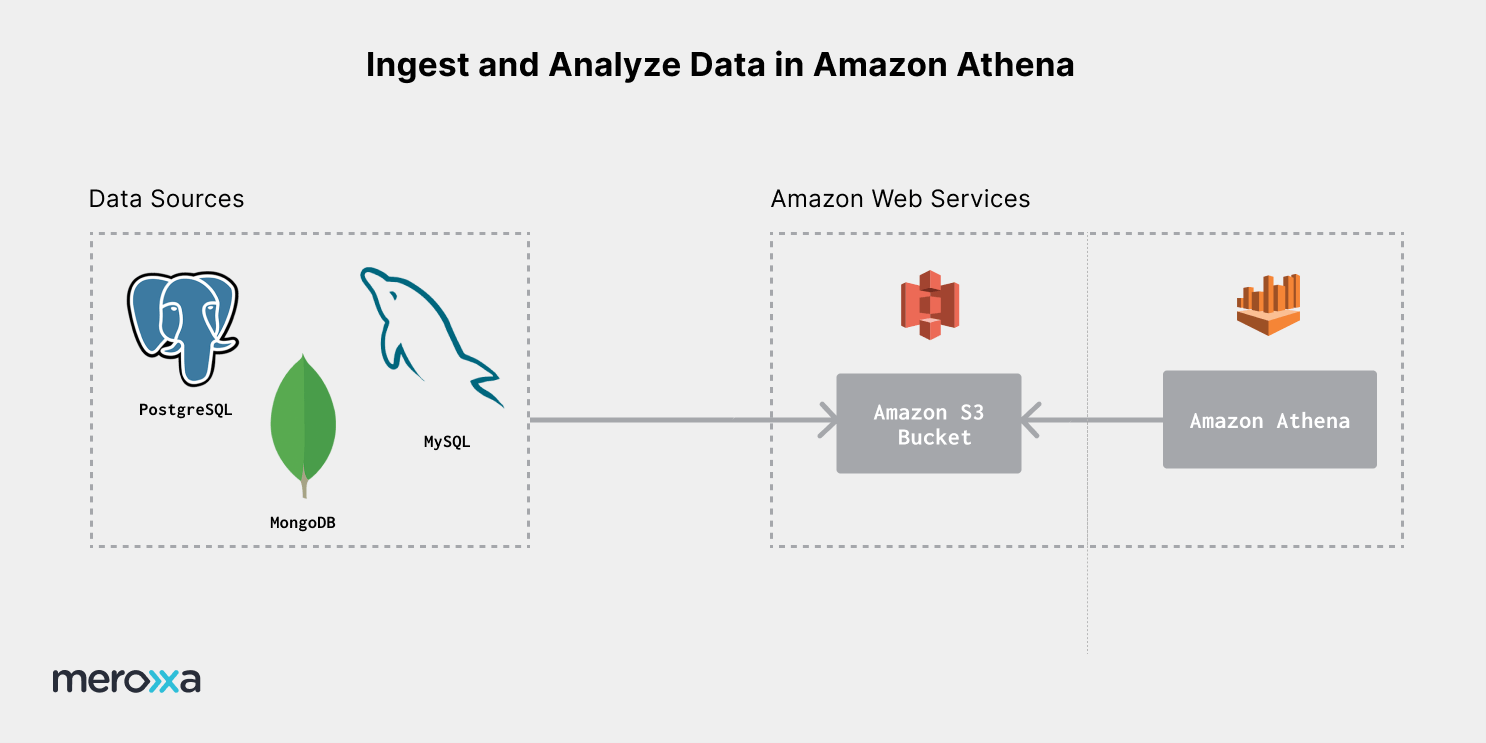
To accomplish ingestion and analysis, you will:
- Send data to Amazon S3.
- Create a table in Amazon Athena.
- Query data.
Send Data to Amazon S3
To build a pipeline to send data to Amazon S3, you can use the Meroxa Dashboard or the Meroxa CLI.
Verifying
Once your pipeline is up and running, you will be able to see data within an S3 bucket:
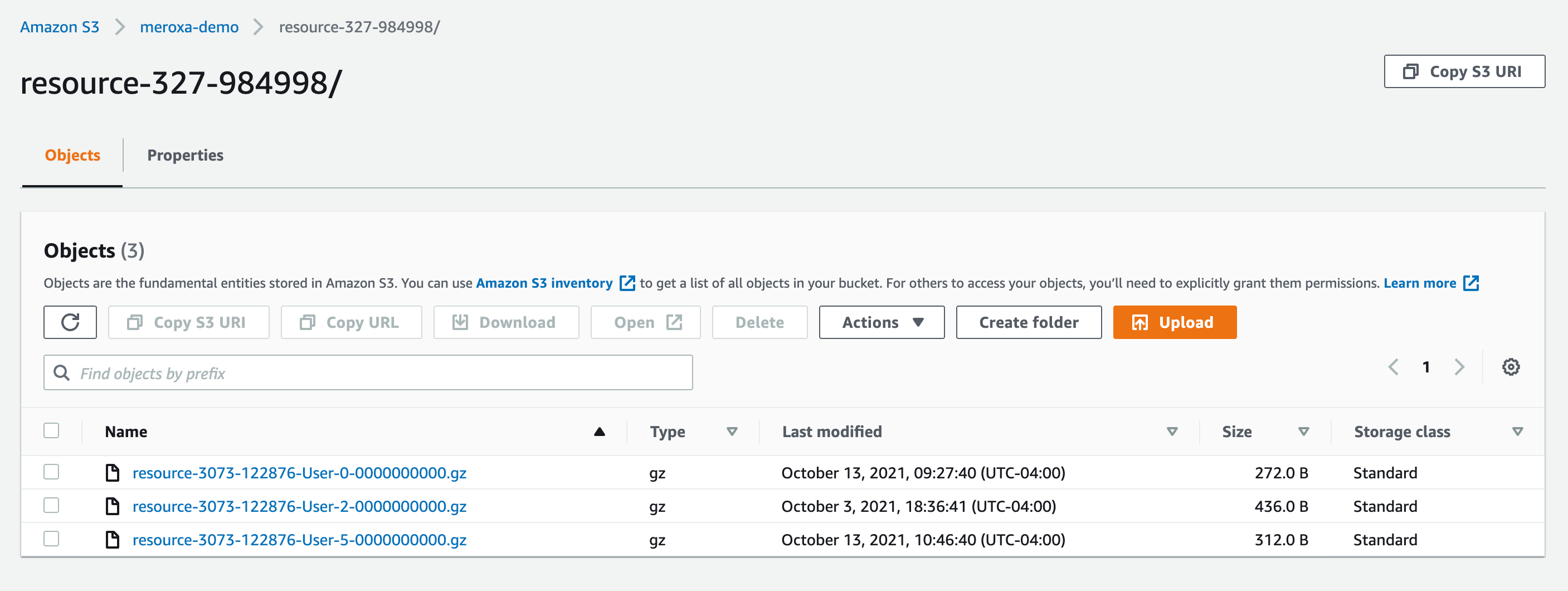
You may change the behavior of the connector with configuration. For example, you can change how the data record is compressed when stored in the bucket.
Create Table in Amazon Athena
Next, you can create a database in Athena.
CREATE DATABASE userdemo
The command above creates a database called userdemo.
Then, you can create a table within this database.
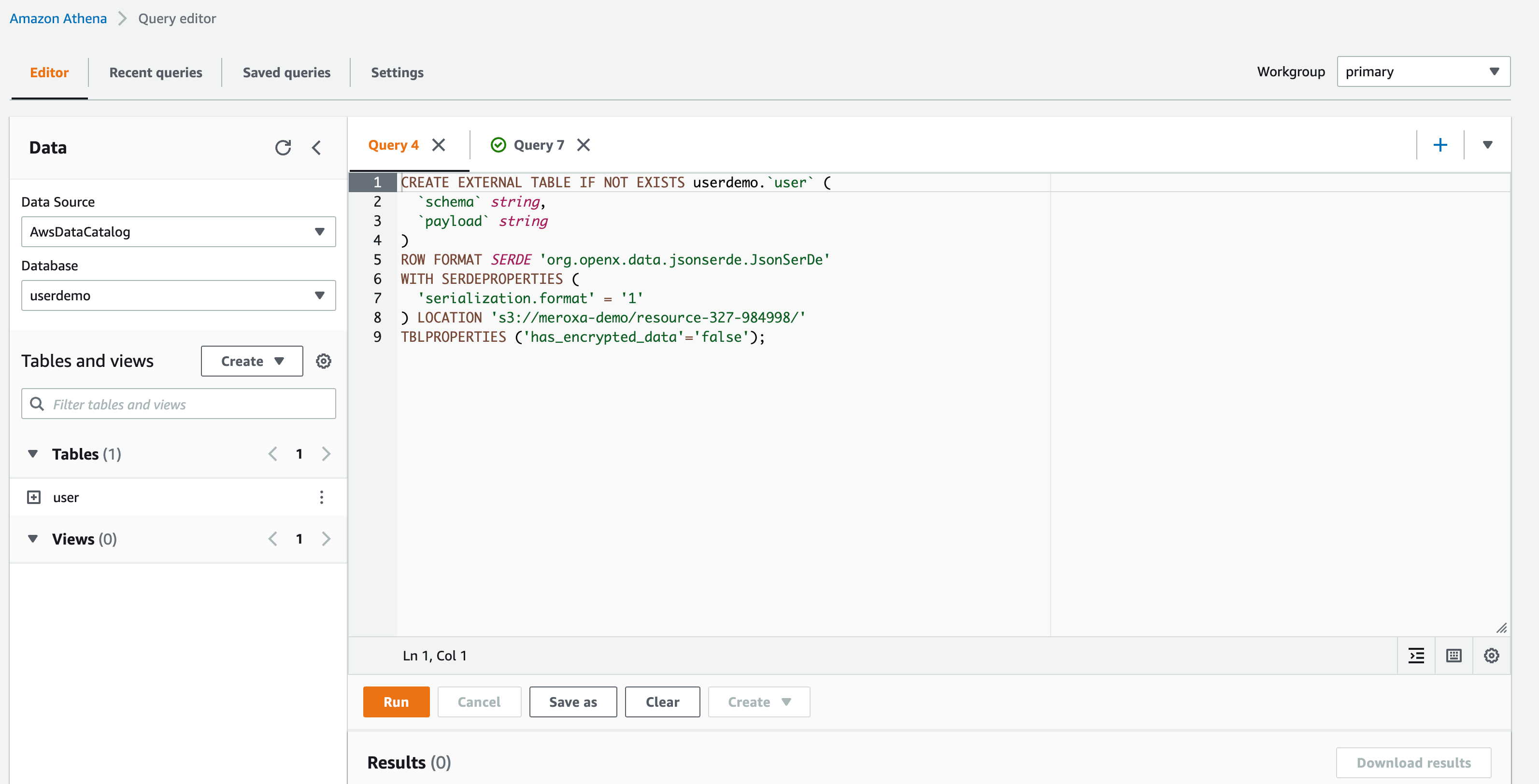
CREATE EXTERNAL TABLE IF NOT EXISTS userdemo.`user` (
`schema` string,
`payload` string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
) LOCATION 's3://your/location/to/folder';
The SQL query above creates a table called user that points to a location in S3 (s3://your/location/to/folder). The table created will have two columns schema and payload. The data records emitted by the connector are in the following format:
{ "schema": <schema>, payload: <event data> }
If desired, you can create mappings from a nested JSON data structure.
Query Data
Now that the table is created, you can use SQL to perform a query:
SELECT * FROM "userdemo"."user" limit 10
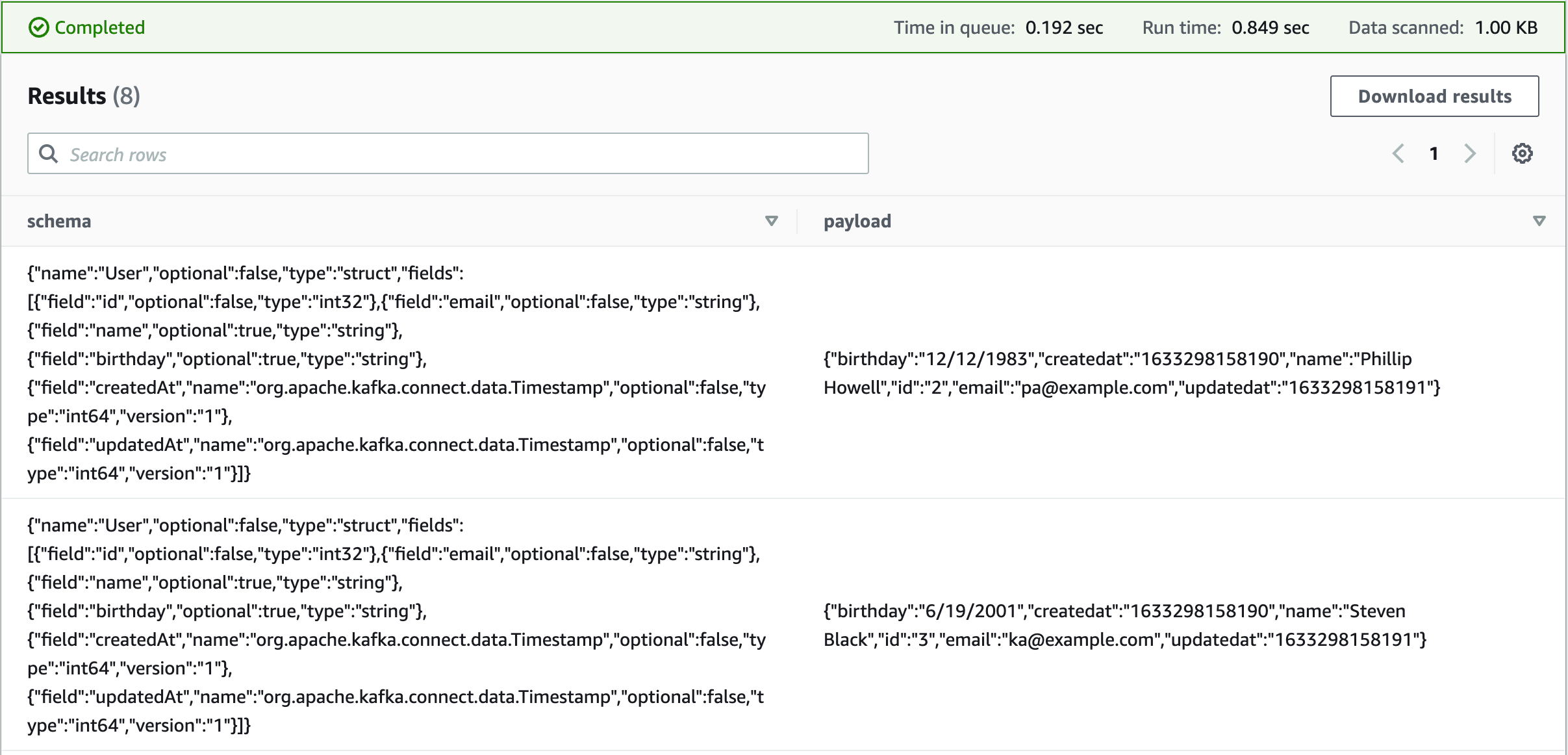
In Athena, you can also parse and extract from JSON data. This is helpful to serialize JSON into columns for easy SQL analysis. For more information, see Amazon's Guide on Extracting data from JSON.
You have now completed this guide and now have a running pipeline to analyze information in S3.
Happy Building 🚀