Built-in Processors
Processors are an optional component of the Conduit Platform that can operate on individual records streaming through a pipeline in your application. They can transform or filter data records based on criteria defined in the built-in processor configuration.
Built-in processors perform a list of supported operations. You may use or combine more than one built-in processor to achieve your desired flow of data.
Configure a built-in processor
There are two ways to configure built-in processors in an application on the Conduit Platform: On connectors and on pipelines. In both cases, processors are executed in the order in which they are configured—starting from the first processor at the top and proceeding down to the last.
Connectors
One or more built-in processors may be configured to source or destination connectors within an application.
It can be configured by clicking the [+] attached to the connector node:
Source: It only receives data records originating from the source it belongs to.
Destination: It only receives data records sent to the destination it belongs to.
Pipelines
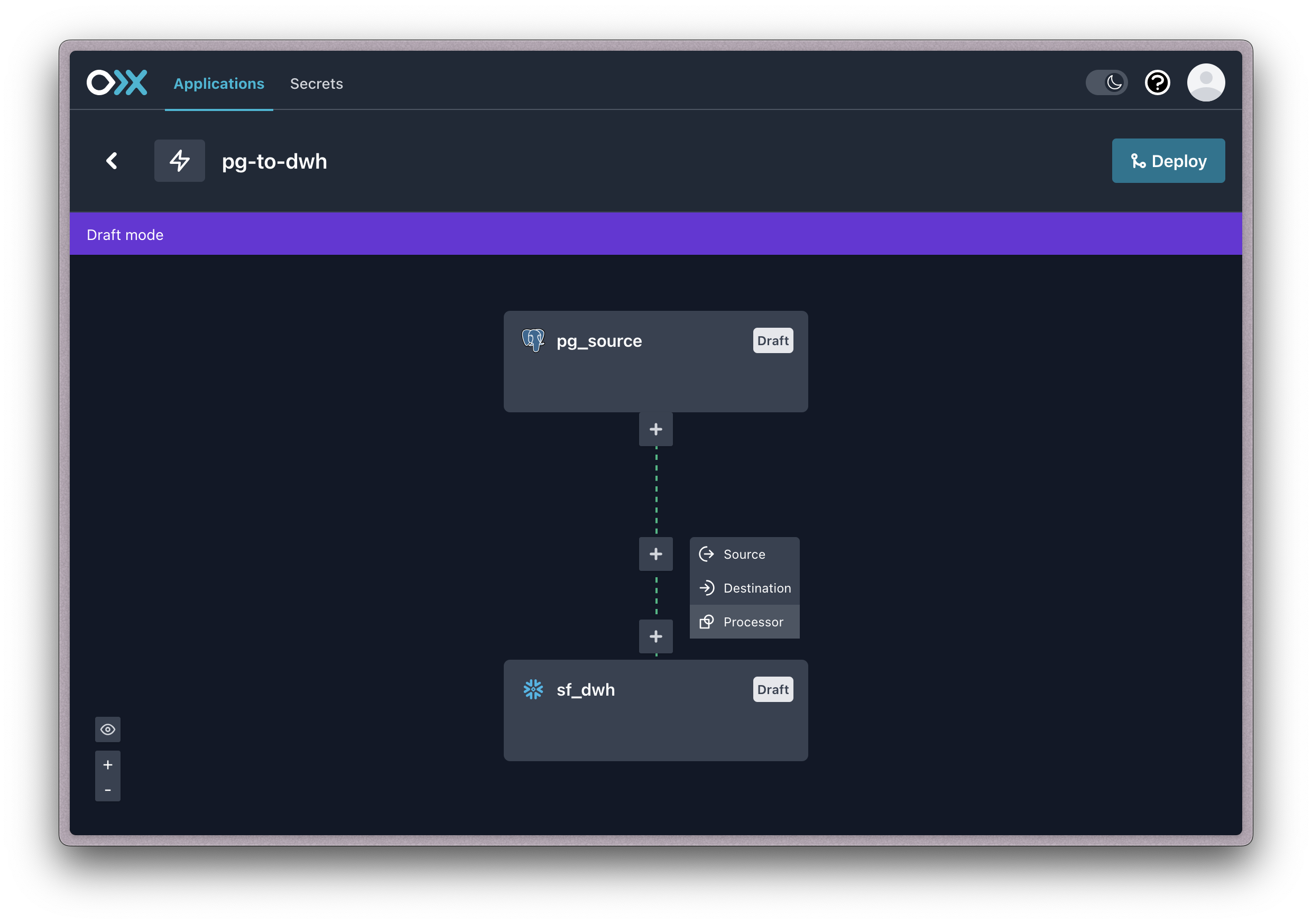
One or more built-in processors may be configured to a pipeline within an application.
When a built-in processor is configured to a pipeline, it will receive data records streaming through the pipeline, regardless of the source they originate from or the destination they are being sent to.
It can be configured by clicking the [+] attached to the connecting pipeline line on the application.
Configure conditions
There may be specific conditions for when a built-in processor should execute on data. To do this, we add a condition to the built-in processor configuration.
Note: The conditions follow the Go templates format, allowing the use of any function provided by sprig.
If the expression is true, the processor will be executed. Otherwise, the record will continue to stream through the application without being processed.
Example of Condition
In this case, records will be processed by the json.decode builtin processsor when the OpenCDC Metadata contains a key named key which value is equal to expected-value.
{{ eq .Metadata.key "expected-value" }}
Supported operations
To learn more about each built-in processor, refer to the Conduit documentation.
avro.decode: Decodes a field's raw data in the Avro format.avro.encode: Encodes a record's field into the Avro format.base64.decode: Decode a field to base64.base64.encode: Encode a field to base64.custom.javascript: Run custom JavaScript code.field.convert: Convert the type of field.field.exclude: Remove a subset of fields.field.rename: Rename a group of fields.field.set: Set the value of a field.filter: Passes through all data records provided the condiitions of the filter is evalated astrue.json.decode: Decodes a field from JSON raw data (string) to structured data.json.encode: Encodes a field from structured data to JSON raw data (string).unwrap.debezium: Unwraps a Debezium record from the input OpenCDC record.unwrap.kafkaconnect: Unwraps a Kafka Connect record from an OpenCDC record.unwrap.opencdc: Unwraps an OpenCDC record contained in a record field.webhook.http: Triggers an HTTP request for every record.